From a ‘deranged’ provocateur to IBM’s failed AI superproject: the controversial story of how data has transformed healthcare

US health data pioneer Ernest Codman at work on his national registry of patient outcomes, 1925. Roy Mabrey/Boston Medical Library
Just over a decade ago, artificial intelligence (AI) made one of its showier forays into the public’s consciousness when IBM’s Watson computer appeared on the American quiz show Jeopardy! The studio audience was made up of IBM employees, and Watson’s exhibition performance against two of the show’s most successful contestants was televised to a national viewership across three evenings. In the end, the machine triumphed comfortably.
You can listen to more articles from The Conversation, narrated by Noa, here.
One of Watson’s opponents Ken Jennings, who went on to make a career on the back of his gameshow prowess, showed grace – or was it deference? – in defeat, jotting down this commentary to accompany his final answer: “I, for one, welcome our new computer overlords.”
In fact, his phrase had been poached from another American television mainstay, The Simpsons. Jennings’ wry pop culture reference signalled Watson’s reception less as computer overlord and more as technological curio. But that was not how IBM saw it. On the back of this very public success, in 2011 IBM turned Watson toward one of the most lucrative but untapped industries for AI: healthcare.
What followed over the next decade was a series of ups and downs – but mostly downs – that exemplified the promise, but also the numerous shortcomings, of applying AI to healthcare. The Watson health odyssey finally ended in 2022 when it was sold off “for parts”.
There is much to learn from this story about why AI and healthcare seemed so well-suited, and why that potential has proved so difficult to realise. But first we need to revisit the controversial origins of data use in this field, long before electronic computers were invented, and meet one of its American pioneers, Ernest Amory Codman – an elite by birth, a surgeon by training, and a provocateur by nature.
Data’s role in the birth of modern medicine
While the utility of data in a general way had already been clear for several centuries, its collection and use on a massive scale was a feature of the 19th century. By the 1850s, collecting census data had become commonplace. Its use was not merely descriptive; it formed a way to make determinations about how to govern.
The 19th century marked the first time that, as US systems expert Shawn Martin explains, “managers felt the need to tie the information that society collected to things like performance [and] productivity”. This applied to public health as well, where “big data” played a critical role in establishing relationships between populations, their habits and environment (both at home and work), and disease.
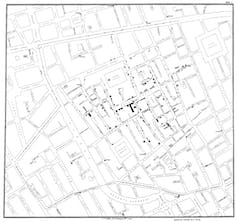
John Snow’s groundbreaking map of cholera cases in central London, 1854.
Wikimedia
A well-known example is John Snow’s discovery of the source of a cholera outbreak in London’s Soho neighbourhood in 1854. Now considered one of epidemiology’s founding fathers, Snow canvassed door to door asking whether the families within had had cholera. His analysis came chiefly in the re-organisation of the data he collected – its plotting on a map – such that a pattern might emerge. This ultimately established not just the extent of the outbreak but also its source, the Broad Street water pump.
For Boston-born Codman, an outspoken medical reformer working at the beginning of the 20th century, such use of data to understand disease was up there as “one of the greatest moments in medicine”.

This article is part of Conversation Insights
The Insights team generates long-form journalism derived from interdisciplinary research. The team is working with academics from different backgrounds who have been engaged in projects aimed at tackling societal and scientific challenges.
Though Codman was involved in many data-driven reforms during his controversial career, one of the most successful was the Registry of Bone Sarcoma, which he established in 1920. His goal was to collect and analyse all of the cases of bone cancer (or suspected bone cancer) from across the US, and to use these to establish diagnostic criteria, therapeutic effectiveness and a standardised nomenclature.
There were a few rules for this registry. Individual doctors who contributed had to send x-rays, case reports and, if possible, tissue samples for examination by the registry’s consulting pathologists and Codman himself. This would ensure both the accuracy and uniformity of pathological analysis. The effort was a success which grew over time: by 1954, when the American College of Surgeons sought a new home for the registry, it contained an impressive 2,400 complete, cross-referenced cases.

Ernest Codman.
National Library of Medicine
On the face of it, Codman’s decision to focus on bone cancer was baffling. It was neither a pressing nor a common concern for doctors across the US. But the disease’s relative rarity was one reason he chose it. Codman felt the amount of data received from his nationwide request would not be overwhelming for his small team of researchers to analyse.
Perhaps more importantly, he knew that studying bone cancer would raise the ire of far fewer of his colleagues than a more common disease might. In a clinical atmosphere in which expertise was understood as a combination of long experience with a dash of intuition – the physician’s “art” – Codman’s touting of data as a better way to obtain knowledge about a disease and its treatment was already being met with vociferous opposition.
It didn’t help that he tended to be inflammatory and provocative in the pursuit of his data-driven goals. At a medical meeting in Boston in 1915, he launched a surprise attack on his fellow practitioners. In the middle of this staid affair, Codman unveiled an 8ft cartoon lampooning his colleagues for their apathy toward healthcare reform and, as he saw it, their wilful ignorance of the limitations of the profession. As one (former) friend put it in the event’s aftermath, Codman’s only hope was that people would take the “charitable” view and consider him not an enemy of the profession but merely “mentally deranged”.

Codman’s 8ft cartoon lampooned medical practices in the early 20th century.
From The Shoulder by E.A. Codman
Undeterred, Codman continued this pugnacious approach to his pioneering work. In a 1922 letter to the prestigious Boston Medical and Surgical Journal, he complained that the surgeons of Massachusetts had been particularly unhelpful to his registry. He explained that he had – politely – asked the 5,494 physicians in the state to “drop him a postal stating whether or not he knew of a case” so that Codman could acquire “the best statistics ever obtained on the frequency of the disease”. To his chagrin, he had received only 19 responses in nearly two years. Needling the journal’s editors and readers simultaneously, he asked:
Is this because your Journal is not read? … [Or] because of the indifference of the medical profession as to whether the frequency of bone sarcoma is known or not?
Codman proposed a questionnaire that would allow the journal to see whether the problem was its lack of readership, or his colleagues’ “inertia, procrastination, disapproval, opposition or disinterest”. A subsequent editorial in response to Codman’s proposal was surprisingly magnanimous:
Whether we will it or not, we are obliged to be irritated, amused or instructed, according to our temperaments, by Dr Codman. Our advice is to be instructed.
An end to elitism?
Despite the establishment’s resistance, submissions to Codman’s registry began to grow such that by 1924, he had enough material to make preliminary comments about bone cancer. For one thing, he had succeeded in standardising the much-contested matter of the proper nomenclature for the disease. This, he exulted, was so significant that it should be likened to the “rising of the sun”.
Codman made this chart of his own life in data.
From The Shoulder by E.A.Codman
The registry also offered up many pieces of “impersonal proof”, as Codman called his data-driven findings, of the rightness of certain theories that individual physicians had promoted. Claims, for example, that combined treatments of “surgery, mixed toxins and radium” were more effective than treatments that relied on any of these alone were borne out by the data.
The registry, as Codman’s colleague Joseph Colt Bloodgood put it, “excited great interest” among practitioners, and not just because it had “influenced the entire medical world to pay more attention to bone tumours”. More importantly, it provided a new model for how to do medical work. Another admiring colleague responded to Bloodgood:
The work of the registry [is] one of the outstanding American contributions to surgical pathology. As a method of study, it shows the necessity of very wide experience before a surgeon is capable of handling intelligently cases of this disease … [It] is impossible for any single individual to claim finality of this sort.
This emphasis on “very wide experience” over the experience of “any single individual” points to another critical reason to prefer data, according to Codman. His goal in changing the method by which medical knowledge was made was not just to get better results. By seeking to undo the image of medicine as an “art” that depended on the wisdom of a select group of preternaturally talented individuals, Codman also threatened to undo the class-ridden reality that underlay this public veneer.
As the efficiency engineer Frank Gilbreth implied in a 1913 article in the American Magazine, if it was true that medicine required no specific intrinsic gifts (monetary or otherwise), then absolutely anybody – whatever their class, race or background – could do it, including “bricklayers, shovellers and dock-wallopers” who were currently shut out of such “high-brow” occupations.
Codman was even more pointed. If data was used to evaluate the outcomes of his physician colleagues, he insisted, it would show that the quality of doctors and hospitals was generally poor. He sniped that they excelled chiefly in “making dying men think they are getting better, concealing the gravity of serious diseases, and exaggerating the importance of minor illnesses to suit the occasion”.

Codman admitted his own social advantages in joining Harvard Medical School.
Detroit Publishing Company/Wikimedia
“Nepotism, pull and politics” were the order of the day in medicine, Codman wrote in one of his most scathing takedowns of his colleagues at the Massachusetts General Hospital. Yet he made himself the centrepiece of this critique, conceding that his entrance to Harvard Medical School had come on the back of “friends and relatives among the well-to-do”. The only difference, he suggested, was that he was willing to own up to it, and to subject himself and his work to the scrutiny of data.
Data’s unflattering view of medicine
Codman was not the only person having a come-to-Jesus moment with data over this period. In the 1920s, the American social science researchers Robert and Helen Lynd collected data in the small US town of Muncie, Indiana, as a way of creating a picture of the “averaged American”.
By the 1930s, the similarly-minded Mass Observation project took off in Britain, intending to collect data about everyday life so as to create an “anthropology of ourselves”. Crucially, both reflected the thinking that also drove Codman: that the right way to know something – a people, a disease – was to produce what seemed a suitably representative average. And this meant the amalgamation of often quite diverse and wide-ranging characteristics and their compression into a single, standard, efficient unit.
The turn from describing representative averages to learning from these averages is probably best articulated in the work of pollsters, whose door-to-door interrogations were aimed at helping a nation to know itself by statistics. In 1948, inspired by their failure to correctly predict the outcome of the US presidential election – one of the most famous psephological errors in the nation’s history – pollsters such as George Gallup and Elmo Roper began to rethink their analytic methods, spinning away from quota sampling and towards random sampling.

The 1948 election was one of the most famous psephological errors in US history.
Clifford K. Berryman/Wikimedia
At the same time, thanks primarily to its military applications, the science of computing began to gather pace. And the growing fascination with knowing the world via data combined with the unparalleled ability of computers to crunch it appeared a match made in heaven.
In a late-in-life preface to his 1934 data-driven magnum opus on the anatomy of the shoulder, Codman had comforted himself with the thought that he was a man ahead of his time. And indeed, just a few years after his death in 1940, statistical analysis began to pick up steam in medicine.
Over the next two decades, figures such as Sir Ronald Fisher, the geneticist and statistician remembered for suggesting randomisation as an antidote to bias, and his English compatriot Sir Austin Bradford Hill, who demonstrated the connection between smoking and lung cancer, also pushed forward the integration of statistical analysis into medicine.

Archie Cochrane.
Cardiff University Library/Cochrane Archive
However, it would take many more years for word to finally leak out that, by data’s measure, both the methodologies of medical research and much of medicine itself was ineffective. In a movement led in part by outspoken Scottish epidemiologist Archie Cochrane, this unflattering statistical view of medicine finally really saw the light of day in the 1960s and 70s.
Cochrane went so far as to say that medicine was based on “a level of guesswork” so great that any return to health after a medical intervention was more a “tribute to the sheer survival power of the minds and bodies” of patients than anything else. Aghast at the revelations embedded in Cochrane’s 1972 book, Random Reflections on Health Services, the Guardian journalist Ann Shearer wrote:
Isn’t it … more than fair to ask what on Earth we – and more particularly, the medical They – have been doing all these years to let the health machine develop with such a lack of quality control?
The answer dates back to Codman’s bone cancer registry half a century earlier. The medical establishment on both sides of the Atlantic had been avoiding with all their might the scrutiny that data would bring.
Computers finally acquire medical currency
Despite their increasing ubiquity in the 1970s and 80s, computers had still only haltingly joined the medical mainstream. Though a smattering of AI applications began to appear in healthcare in the 1970s, it was only in the 1990s that computers really started to acquire some medical currency.
In a page borrowed straight from Codman’s time, the pioneering American biomedical informatician Edward Shortliffe noted in 1993 that the future of AI in medicine depended on the realisation that “the practice of medicine is inherently an information-management task”.
In the US, the Institute of Medicine and the President’s Information Technology Advisory Council released reports highlighting the failures of medicine to fully embrace information technology. By 2004, a newly appointed national coordinator for health information technology was charged with the herculean task of establishing an electronic medical record for all Americans by 2014.

An IBM System 360 computer in 1969.
USDA Forest Service via Wikimedia Commons
This explosion of interest in bringing computers into healthcare made it an enticing and potentially lucrative area for investment. So it is no surprise that IBM celebrated Watson’s winning turn on Jeopardy! in 2011 by putting it to work on an oncology-focused programme with multiple US-based clinical partners selected on the basis of their access to medical data.
The idea was laudable. Watson would do what machine learning algorithms do best: mining the massive amounts of data these institutions had at their disposal, searching for patterns that would help to improve treatment. But the complexity of cancer and the frustratingly unique responses of patients to it, yoked together by data systems that were sometimes incomplete and sometimes incompatible with each other or with machine learning’s methods more generally, limited Watson’s ability to be useful.
One sorry example was Watson’s Oncology Expert Advisor, a collaboration with the MD Anderson Cancer Center in Houston, Texas. This had begun its life as a “bedside diagnostic tool” that pored through patient records, scientific literature and doctors’ notes in order to make real-time treatment recommendations. Unfortunately, Watson couldn’t “read” the doctors’ notes. While good at mining the scientific literature, it couldn’t apply these large-scale discussions to the specifics of the individuals in front of it. By 2017, the project had been shelved.
Elsewhere, at New York City’s famed Memorial Sloan Kettering Cancer Center, clinicians found a more elaborate – and infinitely more problematic – way forward. Rather than relying on the retrospective data that is machine learning’s usual fodder, clinicians invented new “synthetic” cases that were, by virtue of having been invented, infinitely less messy and more complete than any real data could be.
The project re-litigated the “data v expertise” debate of Codman’s time – once more in Codman’s favour – since this invented data had built into it the specifics of cancer treatment as understood by a small group of clinicians at a single hospital. Bias, in other words, was programmed directly in, and those engaged in training the system knew it.
Viewing historical patient data as too narrow, they rationalised that replacing this with data that reflected their own collective experience, intuition and judgment could build into Watson For Oncology the latest and greatest treatments. Of course, this didn’t work any better in the early 21st century than it had in the early 20th.

An early prototype of IBM Watson in 2011.
Clockready/Wikimedia, CC BY-SA
Furthermore, while these clinicians sidestepped the problem of real data’s impenetrable messiness, treatment options available at a wealthy hospital in Manhattan were far removed from those available in the other localities that Watson was meant to serve. The contrast was perhaps starkest when Watson was introduced to other parts of the world, only to find the treatment regimens it recommended either didn’t exist or were not in keeping with the local and national infrastructures governing how healthcare was done there.
Even in the US, the consensus, as one unnamed physician in Florida reported back to IBM, was that Watson was a “piece of shit”. Most of the time, it either told clinicians what they already knew or offered up advice that was incompatible with local conditions or the specifics of a patient’s illness. At best, it offered up a snapshot of the views of a select few clinicians at a moment in time, now reified as “facts” that ought to apply uniformly and everywhere they went.
Many of the elegies written to mark Watson’s selling-off in 2022, having failed to make good on its promise in healthcare, attributed its downfall to the same kind of overpromise and under-delivery that has spelled the end for many health technology start-ups.
Some maintained that the scaling-up of Watson from gameshow savant to oncological wunderkind might have been successful with more time. Perhaps. But in 2011, time was of the essence. To capitalise on the goodwill toward Watson and IBM that Jeopardy! had created, to be the trailblazer into the lucrative but technologically backward world of healthcare, had meant striking first and fast.
Watson’s high-profile failure highlights an overlooked barrier to modern, data-driven healthcare. In its encounters with real, human patients, Watson stirred up the same anxieties that Codman had encountered – difficult questions about what it is exactly that medicine produces: care, and the human touch that comes with it; or cure, and the information management tasks that play a critical role here?
Read more:
AI can excel at medical diagnosis, but the harder task is to win hearts and minds first
A 2019 study of US patient perspectives of AI’s role in healthcare gave these concerns some statistical shape. Though some felt optimistic about AI’s potential to improve healthcare, a vast majority gave voice to fundamental misgivings about relinquishing medicine to machine learning algorithms that could not explain the logic they employed to reach their diagnosis. Surely the absence of a physician’s judgment would increase the risk of misdiagnosis?
The persistence of this worry has quite often resulted in caveating the work of machine learning with reassurances that humans are still in charge. In a 2020 report on the InnerEye project, for example, which used retrospective data to identify tumours on patient scans, Yvonne Rimmer, a clinical oncologist at Addenbrooke’s Hospital in Cambridge, addressed this concern:
It’s important for patients to know that the AI is helping me in my professional role. It’s not replacing me in the process. I doublecheck everything the AI does, and can change it if I need to.
Data’s uncertain role in the future of healthcare
Today, whether a doctor gives you your diagnosis or you get it from a computer, that diagnosis is not primarily based on the intuition, judgment or experience of either doctor or patient. It’s driven by data that has made our cultures of mainstream care relatively more uniform and of a higher standard. Just as Codman foresaw, the introduction of data in medicine has also forced a greater degree of transparency, both in terms of methodologies and effectiveness.
However, the more important – and potentially intractable – problem with this modern approach to health is its lack of representation. As the Sloan Kettering dalliance with Watson began to show, datasets are not the “impersonal proofs” that Codman took them to be.
Even under less egregiously subjective conditions, data undeniably replicates and concretises the biases of society itself. As MIT computer scientist Marzyeh Ghassemi explains, data offers the “sheen of objectivity” while replicating the ethnic, racial, gender and age biases of institutionalised medicine. Thus the tools, tests and techniques that are based on this data are also not impartial.
Ghassemi highlights the inaccuracy of pulse oximeters, often calibrated on light-skinned individuals, for those with darker skin. Others might note the outcry over the gender bias in cardiology, spelled out especially in higher mortality rates for women who have heart attacks.
The landmark human genome announcement in 2000.
The list goes on and on. Remember the human genome project, that big data triumph which has, according to the US National Institutes of Health website, “accelerated the study of human biology and improved the practice of medicine”? It almost exclusively drew upon genetic studies of white Europeans. According to Esteban Burchard at the University of California, San Francisco:
96% of genetic studies have been done on people with European origin, even though Europeans make up less than 12% of the world’s population … The human genome project should have been called the European genome project.
A lack of representative data has implications for big data projects across the board – not least for precision medicine, which is widely touted as the antidote to the problems of impersonal, algorithm-driven healthcare.
Precision or “personalised” medicine seeks to address one of the essential perceived drawbacks of data-based medicine by locating finer-grained commonalities between smaller and smaller subsets of the population. By focusing on data at a genetic and cellular level, it may yet counter the criticism that the data-driven approach of recent decades is too blunt and insensitive a tool, such that “even the most frequently prescribed drugs for the most common conditions have very limited efficacy”, according to computational biologist Chloe-Agathe Azencott.
But personalised medicine still feeds on the same depersonalised data as medicine more generally, so it too is handicapped by data’s biases. And even if it could step beyond the problems of biased data – and, indeed, institutions – the question of its role in the future of our everyday healthcare does not end there.
Even taking the utopian view that personalised medicine might make possible treatments as individual as we are, pharmaceutical companies won’t develop these treatments unless they are profitable. And that requires either prices so high that only the wealthiest of us could afford them, or a market so big that these companies can “achieve the requisite return on investment”. Truly individualised care is not really on the table.
Read more:
In defence of ‘imprecise’ medicine: the benefits of routine treatments for common diseases
If our goal in healthcare is to help more people by being more representative, more inclusive and more attentive to individual difference in the medical everyday of diagnosis and treatment, big data isn’t going to help us out. At least not as things currently stand.
For the story of healthcare data to date has pointed us squarely in the other direction, towards homogenisation and standardisation as medical goals. Laudable as the rationales for such a focus for medicine have been at different moments in our history, our expectations for the potential for machine learning to enable all of us to live longer, healthier lives remain something of a pipe dream. Right now it is still us humans, not our computer overlords, who hold most sway over our individual health outcomes.
Dr Caitjan Gainty is a winner of The Conversation’s Sir Paul Curran award for academic communication

For you: more from our Insights series:
The discovery of insulin: a story of monstrous egos and toxic rivalries
James McCune Smith: new discovery reveals how first African American doctor fought for women’s rights in Glasgow
Drugs, robots and the pursuit of pleasure – why experts are worried about AIs becoming addicts
The inside story of Recovery: how the world’s largest COVID-19 trial transformed treatment – and what it could do for other diseases
To hear about new Insights articles, join the hundreds of thousands of people who value The Conversation’s evidence-based news. Subscribe to our newsletter.
![]()
Caitjan Gainty does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.






